Talend tNormalize helps to normalize the denormalized data so that we can use that cleanse data for further action. This Talend tNormalize component normalizes the source data as we do in the database normalization.
To demonstrate the Talend tNormalize, we used the below-shown text file. As you can notice, the Sales column has multiple entries that are divided by semicolon.
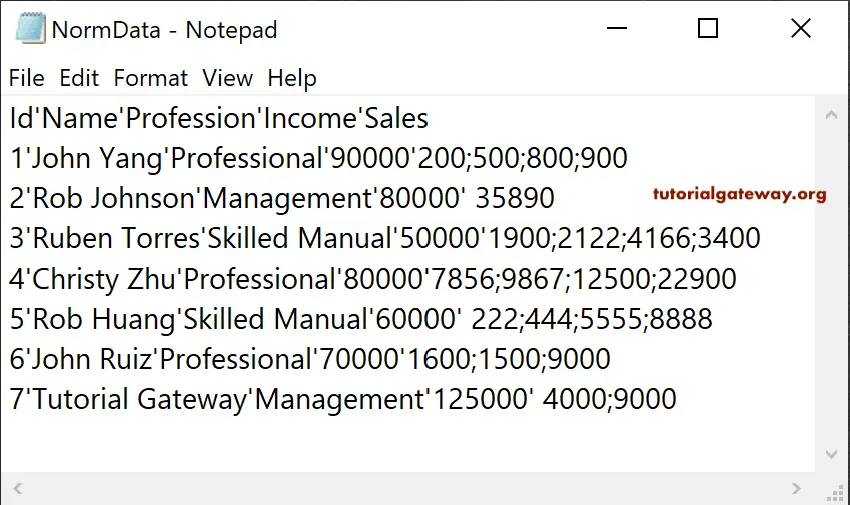
Talend tNormalize Example
Before we started creating a job, we created the File delimited Metadata for the Normalize Source text file. We use this Metadata as the source.

Let me use the same File delimited Metadata as the source of the Talend normalize component.

Next, drag and drop the tNormalize into the job window. As you see from the below tNormalize component tab, it has two options
- Column to normalize: Please select the column that you want to flatten or normalize.
- Item separator: Please type the item that separates the content inside that normalized column.

Please click on the tNormalize Edit Schema button to check the schema or the input and output columns.

Here, we are selecting the Sales column as the normalized column from the drop-down list. Next, we used the semicolon as the item separator.

To display the result of the normalized data, we used the tLogRow. For this, please add the tLogRow and connect the tNormalize to it. Within the tLogRow Component tab, please choose the Table (print values in cells of a table) option. Let me run the Talend tNormalize job and see the result.

We want to store the tNormalize output in the text file to use it as the tDenormalize source. Here, we are saving the result in a text file, including the header, and the columns separated by a comma. Next, run the Talend tNormalize job.

Within the file system, let me open the text file to show you the result.
